C# Join function took all the fun out of trivial programming. In the old days creating a comma separated string out of an array of string was a daunting task for junior programmers.
Some would use the postfix technique. Typically they would iterate through an array adding a comma after each string. At the end they would remove the last comma. But only if string was not empty.
Another approach was to add a comma only if string was not the last in the array. This meant abandoning foreach loop to be able to compare index to array size.
There is a much more elegant solution. It might not be useful in C# because the string class already provides this function, but it is a good to know algorithm.
string Join(string separator, string[] array)
{
StringBuilder sb = new StringBuilder();
string prefix = null;
foreach (string s in array)
{
sb.Append(prefix);
sb.Append(s);
prefix = separator;
}
return sb.ToString();
}
Handle it like a pro. :)
string multiline = string.Join(Environment.NewLine
, "----------------------------------------------"
, "Bill of Materials"
, "----------------------------------------------"
, "Rectangle (10,10) width=30 height=40"
, "Square (15,30) size=35"
, "Ellipse (100,150) diameterH = 300 diameterV = 200"
, "Circle (1,1) size=300"
, "Textbox (5,5) Text=\"sample text\""
, "----------------------------------------------");
I had an interview for a project the other day. The challenge was to conjure a vending machine algorithm. Its main computational problem seems to be the coin-purse management. Consider a very simple loop that given a pound sterling amount in pence -all future examples will also use amounts in pence- finds all the combinations of coins to make it up.
void BruteForce(int total)
{
if (total<=0) return; // Just a sanity check.
for (int p200 = 0; p200 <= total / 200; p200++)
{ // 200p loop
int total200 = total - p200 * 200;
for (int p100 = 0; p100 <= total200 / 100; p100++)
{ // 100p loop
int total100 = total200 - p100 * 100;
for (int p50 = 0; p50 <= total100 / 50; p50++)
{ // 50p loop
int total50 = total100 - p50 * 50;
for (int p20 = 0; p20 <= total50 / 20; p20++)
{ // 20p loop
int total20 = total50 - p20 * 20;
for (int p10 = 0; p10 <= total20 / 10; p10++)
{ // 10p loop
int total10 = total20 - p10 * 10;
for (int p5 = 0; p5 <= total10 / 5; p5++)
{ // 5p loop
int total5 = total10 - p5 * 5;
for (int p2 = 0; p2 <= total5 / 2; p2++)
{ // 2p loop
int total2 = total5 - p2 * 2;
for (int p1 = 0; p1 <= total2; p1++)
{ // 1p loop
int total1 = total2 - p1;
if (
200 * p200
+ 100 * p100
+ 50 * p50
+ 20 * p20
+ 10 * p10
+ 5 * p5
+ 2 * p2
+ p1 == total); // Gotcha!
}
}
}
}
}
}
}
}
}The loop is not optimized. It simply iterates through all possible coin combinations given target amount in p. Nedless to say, the Gotcha! comment in this and all future code samples marks the spot where the solution has been found...but we don't do anything with it.Well, actually, it is slightly optimized. For example if the requested amount is 5p all outer loops (for coins of larger denomination) will only execute once.The following two graphs show the total number of loops executed for totals up to £5 (500p) and the number of solutions found.
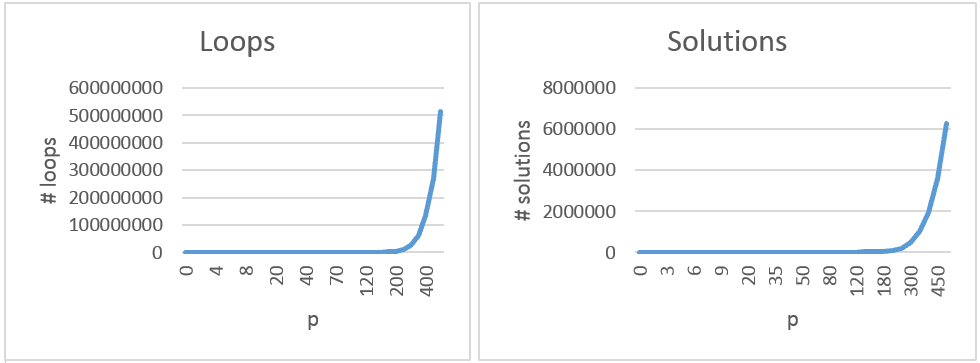
Number of required computations grows exponentionally. And though CPU power is cheap these days, and possibility of vending machine returning more then £5 is minimal - it makes sense to optimize it. Let’s write the same code using recursion.
void RecursiveBruteForce(int coin, int total)
{
if (coin == 0) return; // Exit criteria.
else
for (int qty = total / coin; qty >= 0; qty--)
if (coin * qty == total); // Gotcha!
else RecursiveBruteForce(coin==50?20:coin/2, total-coin*qty);
}That is easier to the eye, but just as greedy. Oh, yes. That coin==50?20:coin/2 is an optimization for finding first smaller coin then current coin from an aging 8-bit assembler programmer ( that would be me :) ). Could be refactored into GetNextCoin(int coin) function to have cleaner, albeit slower code. We transformed loops into a recursive tree search.Now let’s optimize it a bit more by considering the stock of available coins already in the purse. After all we can’t return coins we don’t have. To do this we will assume existence of function int AvailableQty(int coin). No rocket science here:
void RecursiveAvailQty(int coin, int total)
{
if (coin == 0) return; // Exit criteria.
else
for (int qty = Math.Min(AvailableCoins(coin), total / coin); qty >= 0; qty--)
if (coin * qty == total); // Gotcha!
else RecursiveAvailQty (coin==50?20:coin/2, total-coin*qty);
}Since our client does not want tens of coins returned another idea for optimization is to minimize the quantity of coins returned and cut all search tree branches that exceed this.The recursion chooses coins with largest nomination first. This by itself is heuristics and already optimizes the number of coins by directing the search. But there are occasions where this approach does not work. For example: if the vending machine has a supply of 1 x 50p, 3 x 20p, and 10 x 1p and wants to return 60p. By using largest nomination first the first solution will be 1 x 50p, 10 x 1p (11 coins). But wouldn’t you as a client feel much better if the machine returned 3 x 20p (3 coins)?Following code shows algorithm, returning minimal number of coins.
void RecursiveCoinMinimizing(int coin, int total, ref int minqty, int totalqty)
{
if (coin == 0) return; // Exit criteria.
else
for (int qty = Math.Min(AvailableCoins(coin), total / coin); qty >= 0; qty--)
if (coin * qty == total) minqty=Math.Min(minqty, totalqty + qty); // Gotcha!
else if (totalqty + qty < minqty)
RecursiveCoinMinimizing(coin==50?20:coin/2, total-coin*qty, ref minqty, totalqty+qty);
}
To summarize our optimizations:- Our heuristics starts with coins with largest denomination first.
- It cuts all imposible tree branches (that would require quantities of coins we don’t have).
- It then minimizes the quantity coins returned to the client.
- And cuts all tree branches that would contain larger quantity of coins then the solution that we have already found.
Because we start with coins with largest denomination, gradually reducing the quantity of coins with large denomination will increase the total quantity of coins in potential solutions and increase the possibility for the branch to be cut early.
Here is the Coin Minmizing Algorithm at work.
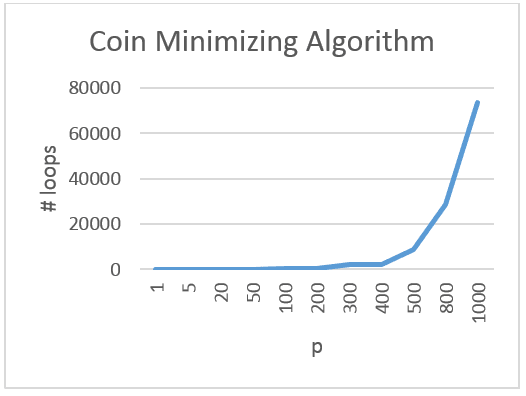
Given unlimited coins in the purse the initial brute force algorithm without any optimization would need to loop 513.269.189 times to find all possible combinations for paying out £5. The Coin Minimizing Algorithm would need to loop only 8.774 times. Even returning £10 can be achieved in real time on an average embedded hardware. If we limit inserting of coins to max. £10 then this solution is considered relatively safe.
So let us call it a day here. :) Sure – there are other optimizations possible. But 1) vending machines are not developed in an evening; these are serious revenue generating softwares and they need serious attention, and 2) this is illustrative enough to shows the approach taken.
Besides speed further optimizations could also include strategies for example defensive behaviour by the vending machine to theoretically minimize the number of failed transactions. This could, perhaps, be done by asset allocation (assigning each denumeration a % of total quantity). And then making rare coins –according to asset allocation- more “expensive” thus directing the search and computing utility value of each generated solution.
Visual Studio automatically creates the AssemblyInfo.cs for every project in the Properties directory. Initially the file looks like this:
using System.Reflection;
using System.Runtime.CompilerServices;
using System.Runtime.InteropServices;
// General Information about an assembly is controlled through the following
// set of attributes. Change these attribute values to modify the information
// associated with an assembly.
[assembly: AssemblyTitle("ASMINFO")]
[assembly: AssemblyDescription("")]
[assembly: AssemblyConfiguration("")]
[assembly: AssemblyCompany("")]
[assembly: AssemblyProduct("ASMINFO")]
[assembly: AssemblyCopyright("Copyright © 2015")]
[assembly: AssemblyTrademark("")]
[assembly: AssemblyCulture("")]
// Setting ComVisible to false makes the types in this assembly not visible
// to COM components. If you need to access a type in this assembly from
// COM, set the ComVisible attribute to true on that type.
[assembly: ComVisible(false)]
// The following GUID is for the ID of the typelib if this project is exposed to COM
[assembly: Guid("3b474425-406a-4053-ab89-4cb4aafaf3b1")]
// Version information for an assembly consists of the following four values:
//
// Major Version
// Minor Version
// Build Number
// Revision
//
// You can specify all the values or you can default the Build and Revision Numbers
// by using the '*' as shown below:
// [assembly: AssemblyVersion("1.0.*")]
[assembly: AssemblyVersion("1.0.0.0")]
[assembly: AssemblyFileVersion("1.0.0.0")]You commonly shrink it to only include fields that are needed. [assembly: AssemblyTitle("Project title.")]
[assembly: AssemblyDescription("Project description.")]
[assembly: AssemblyCompany("My company.")]
[assembly: AssemblyProduct("Product name.")]
[assembly: AssemblyCopyright("Copyright © 2015 My Company Ltd")]
[assembly: AssemblyTrademark("XYZ™")]
[assembly: AssemblyVersion("1.0.*")]This article is about reading these values from the assembly.To do this let us start a class. I shall call it AssemblyInfo but if you dislike duplicate file names in the project feel free to call it AssemblyInfoReader.
public class AssemblyInfo
{
private Assembly _assembly;
public AssemblyInfo(Assembly assembly) { _assembly = assembly; }
}The class contains a private assembly reference from which we would like to read the values and a constructor. You can pass it the executing assembly, the calling assembly, etc. Think about prefixing the function which obtains the assembly reference with the [MethodImpl(MethodImplOptions.NoInlining)] attribute. Otherwise the body of the function might get inlined and return invalid reference.
Now that we have a class we can write functions to help us read the values. For some attributes this is easy as they are already exposed by existing classes. For example the assembly version /note: this is not the same as assembly file version/ can be read like this:
private Version ReadAssemblyVersion()
{
if (_assembly != null)
return _assembly.GetName().Version;
else
return null;
}The version structure will provide you with major version, minor version, build number and revision. Note that when you use "1.0.*" the build number will be equal to the number of days since Jan 1, 2000 local time, and the revision will be equal to the number of seconds since midnight local time, divided by 2. So to annoy the guy /or imaginary guy/ responsible for quality assurance in your company you could actually exploit this to obtain date and time of build.Reading other values requires a bit of reflection. We must first obtain the correct assembly attribute and then read the correct property value. So here is a function to do just that. Provided attribute type as template parameter T and property name as string it returns property value.
private string ReadCustomAttributeValue<T>(string propertyName)
{
if (_assembly != null) // Just in case.
{
object[] customAttributes = _assembly.GetCustomAttributes(typeof(T), false);
// Don't try to understand this. :)
if ((customAttributes != null) && (customAttributes.Length > 0))
return typeof(T).GetProperty(propertyName).GetValue
(customAttributes[0], null).ToString();
}
return string.Empty;
}To read company name simply create a new property like thispublic string Company { get { return ReadCustomAttributeValue<AssemblyCompanyAttribute>("Company"); } }Here are one liners to read all values as properties.public string Company { get { return ReadCustomAttributeValue<AssemblyCompanyAttribute>("Company"); } }
public string Version { get { return ReadAssemblyVersion() != null ? string.Format("{0}.{1}",ReadAssemblyVersion().Major,ReadAssemblyVersion().Minor) : string.Empty; } }
public string Build { get { return ReadAssemblyVersion() != null ? ReadAssemblyVersion().Build.ToString() : string.Empty; } }
public string Revision { get { return ReadAssemblyVersion() != null ? ReadAssemblyVersion().Revision.ToString() : string.Empty; } }
public string Product { get { return ReadCustomAttributeValue<AssemblyProductAttribute>("Product"); } }
public string Copyright { get { return ReadCustomAttributeValue<AssemblyCopyrightAttribute>("Copyright"); } }
public string Title { get { return ReadCustomAttributeValue<AssemblyTitleAttribute>("Title"); } }
public string Description { get { return ReadCustomAttributeValue<AssemblyDescriptionAttribute>("Description"); } }
public string Trademark { get { return ReadCustomAttributeValue<AssemblyTrademarkAttribute>("Trademark"); } }We're almost done. Let us store some custom values to the assembly. For example: assembly service contact /an email/. The elegant way to do this is to create our own attribute.[AttributeUsage(AttributeTargets.Assembly)]
public class AssemblyContactAttribute : Attribute
{
private string _contact;
public AssemblyContactAttribute() : this(string.Empty) {}
public AssemblyContactAttribute(string contact) { _contact = contact; }
public string Contact { get { return _contact; } }
}Then include it into our AssemblyInfo.cs file.[assembly: AssemblyTitle("Project title.")]
[assembly: AssemblyDescription("Project description.")]
[assembly: AssemblyCompany("My company.")]
[assembly: AssemblyProduct("Product name.")]
[assembly: AssemblyCopyright("Copyright © 2015 My Company Ltd")]
[assembly: AssemblyTrademark("XYZ™")]
[assembly: AssemblyVersion("1.0.*")]
[assembly: AssemblyContact("support@my-company.com")]
And finally; extend our class with a new property to read this value.
public string Contact { get { return ReadCustomAttributeValue<AssemblyContactAttribute>("Contact"); } }There. Now we're done.
The issue is to size the picture to fit into given window without distorting it. I found many über complicated solutions on the internet so I ended up writing my own. Here's the algorithm in prose:
Find the factor by which you need to multiply your picture's width and height. Try using outer height / inner height and if the width doesn't fit, use outer width / inner width.Here's the code fragment.
private float ScaleFactor(Rectangle outer, Rectangle inner)
{
float factor = (float)outer.Height / (float)inner.Height;
if ((float)inner.Width * factor > outer.Width) // Switch!
factor = (float)outer.Width / (float)inner.Width;
return factor;
}
To fit picture rectangle (pctRect) to window rectangle (wndRect) call it like thisfloat factor=ScaleFactor(wndRect, pctRect); // Outer, inner RectangleF resultRect=new RectangleF(0,0,pctRect.Width*factor,pctRect.Height*Factor)