C# Join function took all the fun out of trivial programming. In the old days creating a comma separated string out of an array of string was a daunting task for junior programmers.
Some would use the postfix technique. Typically they would iterate through an array adding a comma after each string. At the end they would remove the last comma. But only if string was not empty.
Another approach was to add a comma only if string was not the last in the array. This meant abandoning foreach loop to be able to compare index to array size.
There is a much more elegant solution. It might not be useful in C# because the string class already provides this function, but it is a good to know algorithm.
- string Join(string separator, string[] array)
- {
- StringBuilder sb = new StringBuilder();
- string prefix = null;
- foreach (string s in array)
- {
- sb.Append(prefix);
- sb.Append(s);
- prefix = separator;
- }
- return sb.ToString();
- }
Handle it like a pro. :)
- string multiline = string.Join(Environment.NewLine
- , "----------------------------------------------"
- , "Bill of Materials"
- , "----------------------------------------------"
- , "Rectangle (10,10) width=30 height=40"
- , "Square (15,30) size=35"
- , "Ellipse (100,150) diameterH = 300 diameterV = 200"
- , "Circle (1,1) size=300"
- , "Textbox (5,5) Text=\"sample text\""
- , "----------------------------------------------");
I had an interview for a project the other day. The challenge was to conjure a vending machine algorithm. Its main computational problem seems to be the coin-purse management. Consider a very simple loop that given a pound sterling amount in pence -all future examples will also use amounts in pence- finds all the combinations of coins to make it up.
- void BruteForce(int total)
- {
- if (total<=0) return; // Just a sanity check.
- for (int p200 = 0; p200 <= total / 200; p200++)
- { // 200p loop
- int total200 = total - p200 * 200;
- for (int p100 = 0; p100 <= total200 / 100; p100++)
- { // 100p loop
- int total100 = total200 - p100 * 100;
- for (int p50 = 0; p50 <= total100 / 50; p50++)
- { // 50p loop
- int total50 = total100 - p50 * 50;
- for (int p20 = 0; p20 <= total50 / 20; p20++)
- { // 20p loop
- int total20 = total50 - p20 * 20;
- for (int p10 = 0; p10 <= total20 / 10; p10++)
- { // 10p loop
- int total10 = total20 - p10 * 10;
- for (int p5 = 0; p5 <= total10 / 5; p5++)
- { // 5p loop
- int total5 = total10 - p5 * 5;
- for (int p2 = 0; p2 <= total5 / 2; p2++)
- { // 2p loop
- int total2 = total5 - p2 * 2;
- for (int p1 = 0; p1 <= total2; p1++)
- { // 1p loop
- int total1 = total2 - p1;
- if (
- 200 * p200
- + 100 * p100
- + 50 * p50
- + 20 * p20
- + 10 * p10
- + 5 * p5
- + 2 * p2
- + p1 == total); // Gotcha!
- }
- }
- }
- }
- }
- }
- }
- }
- }
Well, actually, it is slightly optimized. For example if the requested amount is 5p all outer loops (for coins of larger denomination) will only execute once.The following two graphs show the total number of loops executed for totals up to £5 (500p) and the number of solutions found.
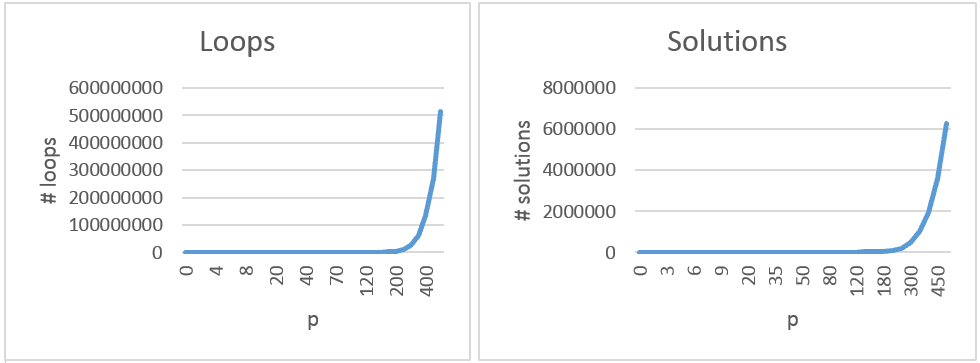
Number of required computations grows exponentionally. And though CPU power is cheap these days, and possibility of vending machine returning more then £5 is minimal - it makes sense to optimize it. Let’s write the same code using recursion.
- void RecursiveBruteForce(int coin, int total)
- {
- if (coin == 0) return; // Exit criteria.
- else
- for (int qty = total / coin; qty >= 0; qty--)
- if (coin * qty == total); // Gotcha!
- else RecursiveBruteForce(coin==50?20:coin/2, total-coin*qty);
- }
Now let’s optimize it a bit more by considering the stock of available coins already in the purse. After all we can’t return coins we don’t have. To do this we will assume existence of function int AvailableQty(int coin). No rocket science here:
- void RecursiveAvailQty(int coin, int total)
- {
- if (coin == 0) return; // Exit criteria.
- else
- for (int qty = Math.Min(AvailableCoins(coin), total / coin); qty >= 0; qty--)
- if (coin * qty == total); // Gotcha!
- else RecursiveAvailQty (coin==50?20:coin/2, total-coin*qty);
- }
The recursion chooses coins with largest nomination first. This by itself is heuristics and already optimizes the number of coins by directing the search. But there are occasions where this approach does not work. For example: if the vending machine has a supply of 1 x 50p, 3 x 20p, and 10 x 1p and wants to return 60p. By using largest nomination first the first solution will be 1 x 50p, 10 x 1p (11 coins). But wouldn’t you as a client feel much better if the machine returned 3 x 20p (3 coins)?Following code shows algorithm, returning minimal number of coins.
- void RecursiveCoinMinimizing(int coin, int total, ref int minqty, int totalqty)
- {
- if (coin == 0) return; // Exit criteria.
- else
- for (int qty = Math.Min(AvailableCoins(coin), total / coin); qty >= 0; qty--)
- if (coin * qty == total) minqty=Math.Min(minqty, totalqty + qty); // Gotcha!
- else if (totalqty + qty < minqty)
- RecursiveCoinMinimizing(coin==50?20:coin/2, total-coin*qty, ref minqty, totalqty+qty);
- }
- Our heuristics starts with coins with largest denomination first.
- It cuts all imposible tree branches (that would require quantities of coins we don’t have).
- It then minimizes the quantity coins returned to the client.
- And cuts all tree branches that would contain larger quantity of coins then the solution that we have already found.
Because we start with coins with largest denomination, gradually reducing the quantity of coins with large denomination will increase the total quantity of coins in potential solutions and increase the possibility for the branch to be cut early.
Here is the Coin Minmizing Algorithm at work.
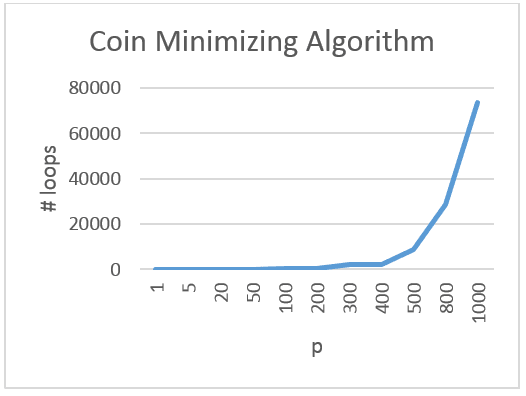
Given unlimited coins in the purse the initial brute force algorithm without any optimization would need to loop 513.269.189 times to find all possible combinations for paying out £5. The Coin Minimizing Algorithm would need to loop only 8.774 times. Even returning £10 can be achieved in real time on an average embedded hardware. If we limit inserting of coins to max. £10 then this solution is considered relatively safe.
So let us call it a day here. :) Sure – there are other optimizations possible. But 1) vending machines are not developed in an evening; these are serious revenue generating softwares and they need serious attention, and 2) this is illustrative enough to shows the approach taken.
Besides speed further optimizations could also include strategies for example defensive behaviour by the vending machine to theoretically minimize the number of failed transactions. This could, perhaps, be done by asset allocation (assigning each denumeration a % of total quantity). And then making rare coins –according to asset allocation- more “expensive” thus directing the search and computing utility value of each generated solution.
Visual Studio automatically creates the AssemblyInfo.cs for every project in the Properties directory. Initially the file looks like this:
- using System.Reflection;
- using System.Runtime.CompilerServices;
- using System.Runtime.InteropServices;
- // General Information about an assembly is controlled through the following
- // set of attributes. Change these attribute values to modify the information
- // associated with an assembly.
- [assembly: AssemblyTitle("ASMINFO")]
- [assembly: AssemblyDescription("")]
- [assembly: AssemblyConfiguration("")]
- [assembly: AssemblyCompany("")]
- [assembly: AssemblyProduct("ASMINFO")]
- [assembly: AssemblyCopyright("Copyright © 2015")]
- [assembly: AssemblyTrademark("")]
- [assembly: AssemblyCulture("")]
- // Setting ComVisible to false makes the types in this assembly not visible
- // to COM components. If you need to access a type in this assembly from
- // COM, set the ComVisible attribute to true on that type.
- [assembly: ComVisible(false)]
- // The following GUID is for the ID of the typelib if this project is exposed to COM
- [assembly: Guid("3b474425-406a-4053-ab89-4cb4aafaf3b1")]
- // Version information for an assembly consists of the following four values:
- //
- // Major Version
- // Minor Version
- // Build Number
- // Revision
- //
- // You can specify all the values or you can default the Build and Revision Numbers
- // by using the '*' as shown below:
- // [assembly: AssemblyVersion("1.0.*")]
- [assembly: AssemblyVersion("1.0.0.0")]
- [assembly: AssemblyFileVersion("1.0.0.0")]
- [assembly: AssemblyTitle("Project title.")]
- [assembly: AssemblyDescription("Project description.")]
- [assembly: AssemblyCompany("My company.")]
- [assembly: AssemblyProduct("Product name.")]
- [assembly: AssemblyCopyright("Copyright © 2015 My Company Ltd")]
- [assembly: AssemblyTrademark("XYZ™")]
- [assembly: AssemblyVersion("1.0.*")]
To do this let us start a class. I shall call it AssemblyInfo but if you dislike duplicate file names in the project feel free to call it AssemblyInfoReader.
- public class AssemblyInfo
- {
- private Assembly _assembly;
- public AssemblyInfo(Assembly assembly) { _assembly = assembly; }
- }
Think about prefixing the function which obtains the assembly reference with the [MethodImpl(MethodImplOptions.NoInlining)] attribute. Otherwise the body of the function might get inlined and return invalid reference.
Now that we have a class we can write functions to help us read the values. For some attributes this is easy as they are already exposed by existing classes. For example the assembly version /note: this is not the same as assembly file version/ can be read like this:
- private Version ReadAssemblyVersion()
- {
- if (_assembly != null)
- return _assembly.GetName().Version;
- else
- return null;
- }
Reading other values requires a bit of reflection. We must first obtain the correct assembly attribute and then read the correct property value. So here is a function to do just that. Provided attribute type as template parameter T and property name as string it returns property value.
- private string ReadCustomAttributeValue<T>(string propertyName)
- {
- if (_assembly != null) // Just in case.
- {
- object[] customAttributes = _assembly.GetCustomAttributes(typeof(T), false);
- // Don't try to understand this. :)
- if ((customAttributes != null) && (customAttributes.Length > 0))
- return typeof(T).GetProperty(propertyName).GetValue
- (customAttributes[0], null).ToString();
- }
- return string.Empty;
- }
- public string Company { get { return ReadCustomAttributeValue<AssemblyCompanyAttribute>("Company"); } }
- public string Company { get { return ReadCustomAttributeValue<AssemblyCompanyAttribute>("Company"); } }
- public string Version { get { return ReadAssemblyVersion() != null ? string.Format("{0}.{1}",ReadAssemblyVersion().Major,ReadAssemblyVersion().Minor) : string.Empty; } }
- public string Build { get { return ReadAssemblyVersion() != null ? ReadAssemblyVersion().Build.ToString() : string.Empty; } }
- public string Revision { get { return ReadAssemblyVersion() != null ? ReadAssemblyVersion().Revision.ToString() : string.Empty; } }
- public string Product { get { return ReadCustomAttributeValue<AssemblyProductAttribute>("Product"); } }
- public string Copyright { get { return ReadCustomAttributeValue<AssemblyCopyrightAttribute>("Copyright"); } }
- public string Title { get { return ReadCustomAttributeValue<AssemblyTitleAttribute>("Title"); } }
- public string Description { get { return ReadCustomAttributeValue<AssemblyDescriptionAttribute>("Description"); } }
- public string Trademark { get { return ReadCustomAttributeValue<AssemblyTrademarkAttribute>("Trademark"); } }
- [AttributeUsage(AttributeTargets.Assembly)]
- public class AssemblyContactAttribute : Attribute
- {
- private string _contact;
- public AssemblyContactAttribute() : this(string.Empty) {}
- public AssemblyContactAttribute(string contact) { _contact = contact; }
- public string Contact { get { return _contact; } }
- }
- [assembly: AssemblyTitle("Project title.")]
- [assembly: AssemblyDescription("Project description.")]
- [assembly: AssemblyCompany("My company.")]
- [assembly: AssemblyProduct("Product name.")]
- [assembly: AssemblyCopyright("Copyright © 2015 My Company Ltd")]
- [assembly: AssemblyTrademark("XYZ™")]
- [assembly: AssemblyVersion("1.0.*")]
- [assembly: AssemblyContact("support@my-company.com")]
- public string Contact { get { return ReadCustomAttributeValue<AssemblyContactAttribute>("Contact"); } }
The issue is to size the picture to fit into given window without distorting it. I found many über complicated solutions on the internet so I ended up writing my own. Here's the algorithm in prose:
Find the factor by which you need to multiply your picture's width and height. Try using outer height / inner height and if the width doesn't fit, use outer width / inner width.Here's the code fragment.
- private float ScaleFactor(Rectangle outer, Rectangle inner)
- {
- float factor = (float)outer.Height / (float)inner.Height;
- if ((float)inner.Width * factor > outer.Width) // Switch!
- factor = (float)outer.Width / (float)inner.Width;
- return factor;
- }
- float factor=ScaleFactor(wndRect, pctRect); // Outer, inner
- RectangleF resultRect=new RectangleF(0,0,pctRect.Width*factor,pctRect.Height*Factor)
The Basic Principles of Remote Debugging
When GNU Debugger is running on one machine and the program being debugged on another – this is called remote debugging. Commonly GNU Debugger is running on a classic PC while the program being debugged is running on some sort of embedded board / or in our case on a ZX Spectrum.
The GNU Debugger for Z80 on PC side knows everything about Z80: the registers, the instructions, the address space. It also knows everything about the debugged program because the debugged program is first loaded into GNU Debugger on PC side and only then sent to ZX Spectrum via serial line by GNU Debugger using special protocol. So the GNU Debugger has the opportunity to examine program’s symbolic information and obtain address of every variable and every function within the program.
- setting a breakpoint at certain address by writing an instruction that returns control to the debugger (RST) there;
- overwriting breakpoints by program’s code on continue,
- returning the values of all registers.
Remote Debugging using FUSE ZX Spectrum Emulator
Remote debugging of code running on an emulator requires a bit more effort. First the serial protocol on ZX Spectrum is converted to named pipe protocol on Unix. Escape sequences are inserted into named pipe data stream to separate data bits from control bits. This makes direct stream communication with the GNU Debugger impossible due to data corruption. And as if this was not bad enough – the GNU Debugger does not speak named pipes. It only “speaks” RS232 and IP. The solution is to write a PC program which talks to both sides in their own language. It communicates with GNU Debugger using IP protocol and with FUSE using named pipes and escape sequences.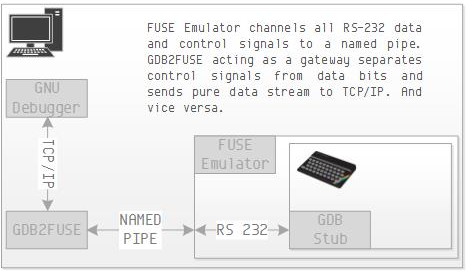
This program is called GDB2FUSE. It has been added to the yx repository. So clone or pull the yx repository to your working folder again. Then go to subfolder yx/tools/gdb2fuse and do make. It will build the command line tool that you need. You may want to copy it to your /usr/local/bin for frequent use.
The GDB Stub for ZX Spectrum
Primarily it requires us to write serial read and write procedures in a way to trick the buggy FUSE Emulator to.
We also need to change breakpoint command because the original gdb-z80 uses RST8 jump instruction for that and on the ZX Spectrum this is reserved for Interface 1 calls. And we do need Interface 1 because serial port is part of it.
To cut the long story short, you can download the code for ZX Spectrum stub from git and compile it. It is locate in yx/tools/gdb-zxspectrum-stub folder and has a Makefile to make things easier for you. This will produce the 48.rom file for you. Currently it only runs on Fuse emulator.
Allright! Let's Do It!
First let us create named pipe files in your home folder. Go to your home folder and do
mkfifo rx tx
gdb2fuse 6666 ~/tx ~/rx
fuse --machine 48 --interface1 --rs232-tx ~/tx --rs232-rx ~/rx --graphics-filter 2x --no-rs232-handshake --rom48 48.romSpectrum's screen should be black. This signals it is in server mode and listening on the serial port for debugger's commands. Now is the time to run the GNU Debugger.
ddd --debugger /usr/local/bin/z80-unknown-coff-gdb &Then go to bottom pane and type
target remote localhost:6666
In this -third- part of our tutorial we are going to compile the GNU Debugger. It was ported to the Zilog Z80 architecture by Leonardo Etcheverry and is available from his git repository. The code is old and you need to apply some hacks for it to compile.
First install some additional tools. These are not part of the standard Ubuntu installation:
sudo apt-get install ncurses-dev flex bison
GNU Debugger also requires the texinfo package. But shall avoid compiling documentation because it is outdated and recent versions of texinfo are too strict for the job.Now fetch gdb-z80 source code by first cd-ing to your ~/dev folder and executing:
git clone https://github.com/legumbre/gdb-z80.git cd gdb-z80You are now ready to compile. Configure the package for cross debugging. Here is the command to do it:
./configure --enable-werror=no --target=z80-unknown-coffThe target of cross compilation is z80. The --enable-werror=no switch turns off error on warning behaviour on newer versions of gcc. The code is too old to pass without warnings and we don't want them to break the compilation.
Before running make we need means to avoid compiling documentation. The tool that we strive to avoid is makeinfo which is part of texinfo package. As you can remember we did not install it. So we are going to make the make think we have it by redirecting it to another tool which will do ... absolutely nothing ... and return success. It just so happens that unix has such a tool. It's called Wine. No, wait. It is called /usr/bin/true.
So here is how we call our make file
make MAKEINFO=trueWe apply the same trick to install gdb-z80 to destination folder
sudo make MAKEINFO=true installIf everything went according to our grand plan there are two new files in your /usr/local/bin folder.
ls /usr/local/bin z80-unknown-coff-gdb z80-unknown-coff-gdbtuiGrand! Now install your favourite GDB GUI. I recommend the Data Display debugger. It is absolutely archaic piece of technology and brings you back to the early days of unix when Motif roamed the earth. Just the right tool for ZX Spectrum development.
Install the DDD
sudo apt-get install dddAnd test our system by passing gdb-z80 to the Data Display Debugger using the --debugger option.
ddd --debugger z80-unknown-coff-gdb &

Yaay. You have a debugger for Z80 on your system. Next time we are going to dwelve into remote debugging and step through a program on your ZX Spectrum emulator.
Till then ... be patient.
So You Wanna Be a ZX Spectrum Developer? (Part II. The Template Application)
1 comment(s) at 5:23 AM
Let us compile'n'run stuff.
In part I. of this turorial you "gitted" yx repository to your local disk. If you followed the tutorial then your target folder was ~/dev/yx.
Open the terminal and set this as your current working folder. Go to tools subfolder (e.g. execute cd ~/dev/yx/tools). There are a bunch of useful tools inside but right now we are only interested in makezxbin. This is an upgraded makebin tool that enables us to use SDCC C compiler for ZX Spectrum development.
You are free to choose z88dk instead. But SDCC is -in my opinion- a more mature environment. It supports C99; has as advanced code optimizer; and produces gdb-z80 compatible symbolic information. z88dk on the other side has superior libraries and ZX Spectrum support.You can compile and deploy makezxbin like this:
cd makezxbin gcc makezxbin.c -o makezxbin sudo mv makezxbin /usr/bin/makezxbinCongratulations! You now have a complete suite of compiler tools needed to develop for ZX Spectrum.
Now go to the ~/dev/yx/apps/template folder and run make. This will create a template application which writes a value of 255 to the first byte of video memory. When it is run the result will be 8 pixel line in the first row of the screen:

The make file will also run the emulator and load your app.You can use this template application as a quick starter for most of your development projects. Let's analyse it.
First there is a pretty straightforward Makefile. Its main target is app.bin. The Makefile assumes that all *.c files ald all *.s files are part of our project. Thus if you add new source files - it will automatically consume them as part of our project.
For easier understanding here are the unconventional tricks of this Makefile:
- it uses your standard gcc (and not SDCC!) compiler to generate .depend file out of *.c and *.h source files for easier compilation,
- it puts crt0.s to 0x8000 and your program to 0x8032, so if you change crt0.s (increasing its length above 0x32 bytes) make sure you update your programs' start address,
- it uses our makezxbin tool to generate correct binary (makebin has a bug and can't be used for this purpose), and
- it uses SDCC all the way but at the end executes appmake +zx --binfile ./app.bin --org 32768 to generate ZX Spectrum tape. appmake is part of z88dk and this is one reason installing both development environments in part I. of this tutorial.
- stores current stack pointer and contents of all registers,
- jumps to start of GSINIT assembler section where the SDCC compiler places all global variables initialization code,
- establishes stack (1KB) and heap global symbols for our program,
- jumps to _main C function, and
- when the main concludes restores registers and stack and returns control to BASIC.
- void main() {
- unsigned char * vmem = 16384;
- (*vmem)=255;
- }
You can examine the locations of your symbols (variables, functions) by opening crt0.map file after compilation.That's it for yoday. Enjoy your experimenting. Our next tutorial will be about debugging.
Here are some useful tips to help you start.
1. Download latest version of Ubuntu Desktop edition. I warmly recommend that you create a separate environment either by installing Ubuntu to a new partition or to a virtual machine. You see ... mid age crises ... come and go. While installed packages ... stay on your disks forever.
2. Download and install FUSE – the ZX Spectrum emulator. Since it lacks Sinclair ROM files, download and install these too.
sudo apt-get install fuse-emulator-gtk spectrum-roms

3. Download and install development suites.
sudo apt-get install sdcc z88dkYou don't actually need both C compilers. But each brings some handy tools that other can use. So install them both.
4. Download git and subversion so you'll be able to check out files from remote repositories
sudo apt-get install git subversion5. Install Z80 language definition for gedit.
5.1. Download z80.lang.zip and extract file z80.lang.

5.2. Modify it by changing this line:
<property name="globs">*.z80</property>to this line:
<property name="globs">*.s</property>You are telling gedit to treat all files with extension *.s as Z80 syntax files.
5.3. Now copy z80.lang into /usr/share/gtksourceview-3.0/language-specs folder.
6. Open terminal, create work folder and download the yx repository.
tomaz@jabba:~$ mkdir dev tomaz@jabba:~$ cd dev tomaz@jabba:~/dev$ git clone https://github.com/tstih/yx.git Cloning into 'yx'... remote: Reusing existing pack: 755, done. remote: Total 755 (delta 0), reused 0 (delta 0) Receiving objects: 100% (755/755), 5.60 MiB | 398.00 KiB/s, done. Resolving deltas: 100% (270/270), done. Checking connectivity... done. tomaz@jabba:~/dev$ cd yx tomaz@jabba:~/dev/yx$ ls apps buddy os README.md tools tomaz@jabba:~/dev/yx$_7. Extend gedit.
7.1. First open file ~/dev/yx/os/rom/crt0.s with gedit. If Z80 language is installed correctly you should see highlighted Z80 code.

7.2. Now press F9 or select menu option View -> Side Panel. When the left pane appears change tab at the bottom of left pane from Documents to File Browser.

That's it for today. In second part of this tutorial we're going to compile and run stuff. Promise.
If you trap an exception inside your control and don't know how to handle it - turn it into an event.
- public event EventHandler<ExceptionEventArgs> Exception;
Introduction
Object oriented programming is an ancient art. When you hear about inversion of control or dependency injection, you should know that these are new names for concepts that have been around for a long time. Today we are going to explore one such ancient technique: a pattern for populating a tree control using the inversion of control; from the early days of computing when resources were sparse.
Let us create a Windows Forms derive Tree View to visualise a hierarchy in an elegant manner. When I say elegant I mean:
- minimal memory signature,
- making control reusable,
- lazy loading data as the user drills down the tree, and
- allow various data objects to be attached to tree nodes.
There is really only one trick behind it: populate top level nodes and check if they have any children. If they do - insert a dummy node under them so that + appears left of the tree node. This will enable tree node expansion. Detect it and populate sub-tree using exactly the same technique.
In 2002 I have published an article on modelling hierarchies using SQL based DBMS. If the data that you visualise uses such storage there are some good tricks there to consider.
The Tree Node
First we need to define a tree node data structure. This is basic building block of our tree structure. It is independent of presentation method. You will be surprised to see that the class has no reference to its parent or its children. Because we are using lazy loading these references are resolved when needed. The code for resolving them is separated to the hierarchy feed class.
- public class Node
- {
- public Node(string unique, string name, bool hasChildren)
- { Unique = unique; Name = name; HasChildren = hasChildren; }
- public string Unique { get; set; }
- public string Name { get; set; }
- public bool HasChildren { get; set; }
- }
The three fields are:
Unique This is the identifier (or the key) of this particular node.
Name This is human readable name for the node.
HasChildren True if node has children and can be expanded.
The Feed
We want the user to be able to use our control for visualizing any hierarchy with minimal effort. Here is a minimalistic tree feed interface. All you really need to implement is a function to query children of a node (or root nodes if parent is not given).
- public interface IHierarchyFeed
- {
- List<Node> QueryChildren(Node parent);
- }
For better understanding of how this feed works let us observe an implementation of this interface for enumerating files and folders in the file system.
- public class FileSysHierarchyFeed : IHierarchyFeed
- {
- private string _rootPath;
- private string _filter;
- public FileSysHierarchyFeed(string rootPath, string filter)
- {
- _rootPath = rootPath;
- _filter = filter;
- }
- public List<Node> QueryChildren(Node parent)
- {
- List<Node> children = new List<Node>();
- if (parent == null)
- AddFilesAndFolders(_rootPath, children);
- else
- AddFilesAndFolders(parent.Unique, children);
- return children;
- }
- #pragma warning disable 168 // Ex variable is never used.
- private void AddFilesAndFolders(string path, List<node> children) {
- foreach (string fso in Directory.EnumerateDirectories(path,"*.*",SearchOption.TopDirectoryOnly)) {
- string unique=Path.Combine(path,fso);
- try { children.Add(new Node(unique, Path.GetFileName(fso), Directory.EnumerateFileSystemEntries(unique).Count() > 0)); }
- catch (UnauthorizedAccessException ex) { } // Ignore unauthorized access violations.
- }
- foreach(string file in Directory.EnumerateFiles(path,_filter)) children.Add(new Node(Path.Combine(path,file),Path.GetFileName(file),false));
- }
- }</node>
Simple, isn’t it? You initialize the feed object with root path and filter, for example c:\ and *.*. When you call QueryChildren with null parameter it returns files and folders from the root path. It uses entire path as the node unique. When calling QueryChildren on a particular node it extracts path from the unique and uses it to enumerate files and folders under this folder.
You can easily write feeder class for database items, remote items, etc.
The TreeView Control
Last but not least - here is the tree view derived control.
- public class NavigatorTree : TreeView
- {
- private class ExpandableNode
- {
- private Node _node;
- private IHierarchyFeed _feed;
- public ExpandableNode(Node node, IHierarchyFeed feed) { _node = node; _feed = feed; }
- public void Expand(TreeNode treeNode) {
- treeNode.TreeView.BeginUpdate();
- treeNode.Nodes.RemoveAt(0); // Remove expandable node.
- foreach (Node childNode in _feed.QueryChildren(_node))
- {
- // Add company.
- TreeNode childTreeNode = treeNode.Nodes.Add(childNode.Name);
- childTreeNode.Tag = childNode;
- // Check if there are any children.
- if (childNode.HasChildren)
- {
- TreeNode toExpandNode = childTreeNode.Nodes.Add("");
- toExpandNode.Tag = new ExpandableNode(childNode, _feed);
- }
- }
- treeNode.TreeView.EndUpdate();
- }
- }
- private IHierarchyFeed _feed;
- public void SetFeed(IHierarchyFeed feed)
- {
- _feed = feed;
- Populate();
- }
- private void Populate()
- {
- Nodes.Clear();
- BeginUpdate();
- foreach (Node node in _feed.QueryChildren(null))
- {
- // Add company.
- TreeNode treeNode = Nodes.Add(node.Name);
- treeNode.Tag = node;
- // Check if there are any children.
- if (node.HasChildren)
- {
- TreeNode toExpandNode = treeNode.Nodes.Add("");
- toExpandNode.Tag = new ExpandableNode(node, _feed);
- }
- }
- EndUpdate();
- }
- protected override void OnBeforeExpand(TreeViewCancelEventArgs e)
- {
- // Check if node has only one child and that child is expandable.
- if (e.Node.Nodes.Count == 1)
- {
- ExpandableNode expandable = e.Node.Nodes[0].Tag as ExpandableNode;
- if (expandable != null)
- expandable.Expand(e.Node);
- }
- }
- }
Voila. It doesn’t get any simpler that that. You initialize tree control by calling SetFeed and providing feed class. For example:
- navigatorTree.SetFeed(new FileSysHierarchyFeed("c:\\", "*.*"));
The control then calls Populate() which in turn populates first tree level and links every tree node with corresponding Node object via the Tag field. If a node has children the populate function adds a fake node of type ExpandableNode under it.
In OnBeforeExpand function the control checks for ExpandableNode. If it founds it - it calls it’s expand function to populate next tree level … and removes the fake node.
This is an advanced sequel to C#: Enums and Strings Are Friends. One of particularly interesting features of an enum is the possibility of extending its values with attributes.
- public enum Digits
- {
- [Arabic("1")]
- [Roman("I")]
- One=1,
- [Arabic("2")]
- [Roman("II")]
- Two,
- [Arabic("3")]
- [Roman("III")]
- Three
- }
On top of that you are able to derive your custom attributes from the Attribute class. By adding properties to this class you can attach a plethora of information to each value of an enum.
- [AttributeUsage(AttributeTargets.Field)]
- public class RomanAttribute : Attribute
- {
- private readonly string _digit;
- public string Digit
- {
- get { return _digit; }
- }
- public RomanAttribute(string title) // url is a positional parameter
- {
- _digit = title;
- }
- }
Luckily we live in the age of generics and reflections. So reading these properties no longer requires hard coded attribute type and target property. You can simply pass attribute type, property type, property name and enum to a function and let reflection do its business.
- // Read [Description] attribute.
- Enum e = Days.Sat;
- string s = e.GetAttributeProperty<DescriptionAttribute, string>("Description");
- Console.WriteLine("Description is {0}", s);
- // Read [DisplayName ] attribute.
- s = e.GetAttributeProperty<DisplayNameAttribute, string>("DisplayName");
- Console.WriteLine("Display name is {0}", s);
- // Find enum value based on [Description].
- Enum ef = e.FindEnumValueByAttributeProperty<DescriptionAttribute, string>("Description","Friday");
- public static class EnumEx
- {
- #region Enum Extensions
- public static PT GetAttributeProperty<AT, PT>(this Enum this_, string propertyName)
- where AT : Attribute
- where PT : class
- {
- // First get all attributes of type A.
- AT[] attributes =
- (this_.GetType().GetField(this_.ToString())).GetCustomAttributes(typeof(AT), false) as AT[];
- if (attributes == null || attributes.Length == 0) // Null or can't cast?
- return null;
- else
- { // We have something.
- AT a = attributes[0];
- PropertyInfo pi = a.GetType().GetProperty(propertyName);
- if (pi != null)
- {
- PT result = pi.GetValue(a, null) as PT;
- return result;
- }
- else
- return null;
- }
- }
- public static Enum FindEnumValueByAttributeProperty<AT, PT>(this Enum this_, string propertyName, PT propertyValue)
- where AT : Attribute
- where PT : class, IComparable
- {
- // First get all enum values.
- Array enums = Enum.GetValues(this_.GetType());
- foreach (Enum e in enums)
- {
- PT p = e.GetAttributeProperty<AT, PT>(propertyName);
- if (p!=null && p.Equals(propertyValue))
- return e;
- }
- return null;
- }
- #endregion // Enum Extensions
- }
UPDATE: It seems like the usage of < and > symbols in code corrupted the listings. Fixed it.
If you need a portable .NET solution for converting RGB to HLS and vice versa there are libraries around to do it. For Windows only using the Shell Lightweight Utility Functions is a simpler alternative.
- [DllImport("shlwapi.dll")]
- static extern int ColorHLSToRGB(int H, int L, int S);
- [DllImport("shlwapi.dll")]
- static extern void ColorRGBToHLS(int RGB, ref int H, ref int L, ref int S);
- // RGB2HLS
- ColorRGBToHLS(ColorTranslator.ToWin32(rgbColor, ref h, ref l, ref s);
- // HLS2RGB
- Color rgbColor=ColorTranslator.FromWin32(ColorHLSToRGB(h, l, s));
Many thanks to John Boker for his concise explanation. What a time saver.
"Margin is on the outside of block elements while padding is on the inside. Use margin to separate the block from things outside it, padding to move the contents away from the edges of the block."
Sometimes you want a function to return an object or null if no object is found. Lazy evaluation makes it easy to automate this behaviour.
- public Person FindPerson(Criteria c)
- {
- Lazy<Person> person = new Lazy<Person>();
- // Code to actually find a person ...
- // ... and populate person.Value
- return person.IsValueCreated ? person.Value : null;
- }
- foreach (Font font in GetFixedFonts())
- {
- // But GetFixedFonts returned null.
- }
You can assure that function always returns an array /even if empty/ by using lazy evaluation too. Here is an example of that.
- public FontFamily[] GetFixedFonts()
- {
- Lazy<List<FontFamily>> fonts = new Lazy<List<FontFamily>>();
- foreach (FontFamily ff in System.Drawing.FontFamily.Families)
- if (IsFixedFontFamily(ff))
- fonts.Value.Add(ff);
- return fonts.Value.ToArray();
- }
You know the drill. Programming a graph takes too much time...use a library...or hire an external consultant. But...is it really so?
Imagine you have two coordinate systems. Your physical screen coordinate system spans from 0 to window's width horizontally and from 0 to window's height vertically. And your imaginary world (i.e. a map) spans from -10.000 to 10.000 horizontally and from 0 to 5000 vertically.
Just to make things a bit more complex you also want to:
- zoom everything on the screen by arbitrary zoom factor, and
- show only part of your map on the screen starting from point T(-3.000, 1000) given in map coordinates, where -3000 is left and 1000 is top coordinate of part of map we would like to display on screen.
Map to Screen
Are you scared yet? Don’t be. Here is the basic formula for converting map coordinate to screen coordinate:

Same formula can be applied to another dimension. For example:

So far ... so trivial. :) Since you start at point T(x,y) you need to put x and y to point to 0,0 on the screen. Afterwards you simply multiply by zoom factor. If factor is 1 then 1 point on the map is converted to 1 point on the screen. If the factor is 1:2 then 1 point on the map is only ½ point on the screen. And so on.
If the axis is a reverse axis then your equation is:

Screen to Map
What if somebody clicks on the screen and we need to find map coordinate of the click? Let us derive this scenario from the above equation:

Deriving same formula for the reverse axis is a good exercise for you, don’t you agree? :)
Fit to Screen
If we want to fit our map inside the screen we must start drawing it at its T=T0 point. We calculate T by using:

No big secrets here. So our left, right point T is at map's min x and min y. And if reverse axis is being used we must use max instead.
The apropriate fit to screen zoom is calculated like this:

If you are using same unit for both axes then there will be only one zoom factor. To still fit map to the screen make sure that you fit larger dimension of both - width or height to fit the screen. Then use the same zoom factor for smaller dimension. This way both are guaranteed to fit the screen.
Calculate Distances
Last but not least ... distances are calculated with a little help from previous calculations. If you have a distance in screen units and you would like to convert to map distance you subtract it from point zero and derive the formula like this:

The distance obviously depends on the zoom factor alone. For better understanding derive the opposite formula and get screen distance from map distance yourself. :)
Coming Next...
So there you have it. Most of these formulas are -in fact- just simplified 4 x 4 matrix translation, usually performed for you by modern 2D graphics engines such as GDI+ or Cairo.
Observing simplicity of graph math one realizes that graphs aren't really such a terrible development effort. It's drawing points, lines and polygons using these formulas to translate coordinates. Zooming is changing the zoom factor, and scrolling is changing the T point. We will take a closer look at these operations in part two of this series.
A singleton is like the Egg of Columbus. Easy after someone had showed you how to do it. Luckily Jon Skeet had showed us how to use lazy evaluation for thread safety. And an unknown contributor of Great Maps had demonstrated the usage of generics for that purpose. So all that is left for me - is to put it all together.
- public sealed class Singleton<T> where T : new()
- {
- private static readonly Lazy<T> instance = new Lazy<T>(() => new T());
- public static T Instance { get { return instance.Value; } }
- private Singleton()
- {
- }
- }
- // Create two server objects pointing to the same instance.
- Server svr1 = Singleton<Server>.Instance;
- Server svr2 = Singleton<Server>.Instance;
- C# In Depth: Implementing the Singleton Pattern in C#
- GMap.NET Singleton Class
So you needed to draw a grid … or a ruler … or another x-y-ish vector graphics and you ended up with code snippets like this everywhere:
- public void Grid(Graphics g, Size size, int step) {
- for (int i = 0; i < size.Width; i+=step)
- {
- g.DrawLine(Pens.Black,
- new Point(i, 0),
- new Point(i, size.Height)
- );
- }
- for (int i = 0; i < _size.Height; i += step)
- {
- g.DrawLine(Pens.Black,
- new Point(0, i),
- new Point(size.Width, i)
- );
- }
- }
- public interface IDirection
- {
- int GetMoving(Size size);
- int GetStatic(Size size);
- void AddMoving(ref int x, ref int y, int step);
- Point GetPoint(int moving, int static_);
- }
- public class VerticalDirection : IDirection
- {
- public int GetMoving(Size size)
- {
- return size.Height;
- }
- public void AddMoving(ref int x, ref int y, int step)
- {
- y += step;
- }
- public Point GetPoint(int moving, int fixed_)
- {
- return new Point(fixed_, moving);
- }
- public int GetStatic(Size size)
- {
- return size.Width;
- }
- }
- class HorizontalDirection : IDirection
- {
- public int GetMoving(System.Drawing.Size size)
- {
- return size.Width;
- }
- public void AddMoving(ref int x, ref int y, int step)
- {
- x += step;
- }
- public Point GetPoint(int moving, int fixed_)
- {
- return new Point(moving, fixed_);
- }
- public int GetStatic(Size size)
- {
- return size.Height;
- }
- }
- public void Grid(Graphics g, Size size, int step)
- {
- Grid(g, size, step, new VerticalDirection());
- Grid(g, size, step, new HorizontalDirection());
- }
- public void Grid(Graphics g, Size size, int step, IDirection direction)
- {
- for (int i = 0; i < direction.GetMoving(size); i += step)
- {
- g.DrawLine(Pens.Black,
- direction.GetPoint(i, 0),
- direction.GetPoint(i, direction.GetStatic(size))
- );
- }
- }
Sometimes you want to know index of the minimal value of an array. I’ve frequently seen programmers using two data structures to accomplish this task: one to hold the index and the other to hold the value (i.e. current minimum) while iterating. Unless you need to optimize your code for speed you really only need an integer for this task.
- int find_min(int* vals, int len)
- {
- int mindx= 0;
- for (int i = 1; i < len; i++)
- if (vals[i] < vals[mindx]) mindx= i;
- return mindx;
- }
I've been searching for this for three years and now my collection is complete.

GNU Make is a decent tool. But due to the fact that I commonly create only a handful of Makefiles per project and that its syntax is easy to forget (or -perhaps- hard to remember) - it often takes me an hour before I create a new generic Makefile for a project.
More often then not I end up analysing and recycling an existing one from one of my previous projects. Thus I wrote a generic Windows starter that will work on any folder that contains .c and .h files as long as you have The GNU C Compiler Suite and Make installed on your machine.
Simply add this Makefile to your folder and change the target (the default is "buddy.exe") to the name of your desired exe output file. Make sure that one .c file contains the main function and the rest will be done by the build system.
The main tricks being used are:
1. Obtaining list of all *.c files in folder...
SRCS = $(wildcard *.c)2. ...using it to generate all object files.
OBJS = $(patsubst %.c,%.o,$(SRCS))3. Creating dependency file named .depend by using -MM switch on gcc (i.e. fake compilation step).
$(CC) $(CFLAGS) $(SRCS) -MM >> .depend4. Including dependency file into makefile using -include (minus means it will not complain if the file is not there i.e. on the first run).
-include .depend5. And last but not least: redirection of stderr to NUL to prevent DEL command from complaining when there are no matching files.
del *.o 2>NULHere is the entire Makefile.
Following step-by-step instructions by Adam J. Kunen I was able to compile my own gnu arm tool-chain on Ubuntu Linux 12.10.
I used following packages:
- binutils-2.23
- gcc-4.8.1 (Adam also recommends downloading packages gcc-core and g++ but I skipped those)
- gdb-7.6
- newlib-2.0.0
../../src/gcc-4.8.1/configure --target=arm-none-eabi --prefix=$MYTOOLS --enable-interwork --enable-multilib --enable-languages="c,c++" --with-newlib --with-headers=../../src/newlib-2.0.0/newlib/libc/include --with-system-zlib
UPDATE: Unfortunately this fix has some issues. It will not build libgcc. Seeking for a better solution.
This is a little pet project of mine. It provides me with sort of in-depth understanding of embedded designs, programming languages and operating systems that only a hands-on approach can.
A picture is worth a thousand words.
Source: Dr. Dobb's Journal
Mapping database tables to C++ classes is a common challenge. Let us try to map a database table person to a class.
- using namespace boost::gregorian;
- using namespace std::string;
- class person {
- public:
- string first_name;
- string last_name;
- date date_of_birth;
- int height;
- float weight;
- };
Under perfect conditions this would work just fine. But in practice when rolling out our database layer (with elements of RDBMS-2-OO) several problems arise. One of them is handing null values.
In C# we would use (...and strongly typed datasets do) nullable types.
- public class Person {
- public:
- string FirstName;
- string LastName;
- date DateOfBirth;
- int? Height; // Nullable type.
- float? Weight; // Nullable type.
- };
However there is no similar language construct in C++. So we will have to create it. Our todays' goal is to add built in value types the ability to be null. And to be able to detect when they are null.
We will create new types but we desire -just like in C#- that they behave like existing built in types.
So why not deriving from built in types?
- class int_ex : int {
- }
I've been thinking long and hard about the appropriate answer to this good question. And finally I came up with the perfect argument why this is a bad idea. It's because it won't compile.
Luckily we have templates. Let us start by declaring our class having a simple copy constructor.
- template <typename T>
- class nullable {
- private:
- T _value;
- public:
- // Copy constructor.
- nullable<T>(T value) {
- _value=value;
- }
- };
With this code we have wrapped built in value type into a template. Let us explore possibilities of this new type.
- int n=10;
- nullable<int> i=20; // This actually works!
- nullable<int> j=n; // This too.
- nullable<int> m; // This fails because we have no default constructor.
This is a good start. Since we have not defined a default constructor and we have defined a copy constructor the compiler hasn't generated the default constructor for us. Thus last line won't compile. Adding the default constructor will fix this. The behavior of the ctor will be to make value type equal to null. For this we will also add _is_null member to our class. Last but not least we will add assignment operator to the class.
- template <typename T>
- class nullable {
- private:
- T _value;
- bool _is_null;
- public:
- // Copy ctor.
- nullable<T>(T value) {
- _value=value;
- _is_null=false;
- }
- // Default ctor.
- nullable<T>() {
- _is_null=true;
- }
- // Assignment operator =
- nullable<T>& operator=(const nullable<T>& that) {
- if (that._is_null) // Make sure null value stays null.
- _is_null=true;
- else {
- _value=that._value;
- _is_null=false;
- }
- return *this;
- }
- };
Now we can do even more things to our class.
- int n=10;
- nullable<int> i=20; // Works. Uses copy constructor.
- nullable<int> j; // Works. Uses default ctor. j is null.
- j=n; // Works. Uses copy constructor + assignment operator.
- j=i; // Works. Uses assignment operator.
Next we would like to add the ability to assign a special value null to variables of our nullable type. We will use a trick to achieve this. We will first create a special type to differentiate nulls' type from all other types. Then we will add another copy constructor further specializing template the null type.
- class nulltype {
- };
- static nulltype null;
- template <typename T>
- class nullable {
- private:
- T _value;
- bool _is_null;
- public:
- // Assigning null.
- nullable<T>(nulltype& dummy) {
- _is_null=true;
- }
- // Copy ctor.
- nullable<T>(T value) {
- _value=value;
- _is_null=false;
- }
- // Default ctor.
- nullable<T>() {
- _is_null=true;
- }
- // Assignment operator =
- nullable<T>& operator=(const nullable<T>& that) {
- if (that._is_null) // Make sure null value stays null.
- _is_null=true;
- else {
- _value=that._value;
- _is_null=false;
- }
- return *this;
- }
- };
Let us further torture our new type.
- nullable<int>m=100; // Works! m=100!
- nullable<int>j; // Works! j is null.
- nullable<int>n=j=m; // Works! All values are 100.
- nullable<int>i=null; // Works! i is null.
Our type is starting to look like a built in type. However we still can't use it in expressions to replace normal value type. So let's do something really dirty. Let us add a cast operator into type provided as template argument.
- // Cast operator.
- operator T() {
- if (!_is_null)
- return _val;
- }
Automatic casts are nice and they work under perfect conditions. But what if the value of nullable type is null? We'll test for the null condition in our cast operator and throw a null_exception.
Throwing an exception is an act of brutality. We would like to allow user to gracefully test our type for null value without throwing the exception. For this we will also add is_null() function to our class.
- class null_exception : public std::exception {
- };
- class null_type {
- };
- static null_type null;
- template <typename T>
- class nullable {
- private:
- T _value;
- bool _is_null;
- public:
- // Assigning null.
- nullable<T>(null_type& dummy) {
- _is_null=true;
- }
- // Copy ctor.
- nullable<T>(T value) {
- _value=value;
- _is_null=false;
- }
- // Default ctor.
- nullable<T>() {
- _is_null=true;
- }
- // Assignment operator =
- nullable<T>& operator=(const nullable<T>& that) {
- if (that._is_null) // Make sure null value stays null.
- _is_null=true;
- else {
- _value=that._value;
- _is_null=false;
- }
- return *this;
- }
- // Cast operator.
- operator T() {
- if (!_is_null)
- return _value;
- else
- throw (new null_exception);
- }
- // Test value for null.
- bool is_null() {
- return _is_null;
- }
- };
We're almost there. Now the following code will now work with new nullable type.
- nullable<int> i; // i is null
- nullable<int> j=10;
- i=2*j; // i and j behave like integer types.
- j=null; // you can assign null to nullable type
- if (j.is_null()) { // you can check j
- int n=j+1; // Will throw null_exception because j is null
- }
There are still situations in which nullable types do not act or behave like the built in value types.
- // This will fail...
- for(nullable<int> i=0; i<10;i++) {
- }
To fix this we need to implement our own ++ operator.
- // Operator ++ and --
- nullable<T>& operator++() {
- if (!_is_null) {
- _value++;
- return (*this);
- } else
- throw (new null_exception);
- }
- nullable<T> operator++(int) {
- if (!_is_null) {
- nullable<T> temp=*this;
- ++(*this);
- return temp;
- } else
- throw (new null_exception);
- }
This is it. We have developed this type to a point where it serves our purpose. To enable us to write database layer.
- using namespace boost::gregorian;
- using namespace std::string;
- class person {
- public:
- string first_name;
- string last_name;
- date date_of_birth;
- nullable<int> height;
- nullable<float> weight;
- };
There's still work to be done. Implementing remaining operators (such as ==). Finding new flaws and differences between our type and built in types. I leave all that to you, dear reader. If you extend the class please share your extensions in the comments section for others to use. Thank you.
I expected most of my readership to come from Africa, India and Asia. But they are from Silicon Valley, California.
I have always wanted to know how ./configure does its magic. To a Gnu newbie the Gnu Build System seems utterly complex. Available manuals for Autoconf, Automake and Libtool are several hundred pages of difficult-to-read text. Learning curve is steep. Way too steep to produce a simple script!
But then -last week as I googled around- I found these gems:
- Using Automake and Autoconf with C++
- Using C/C++ libraries with Automake and Autoconf
- Building C/C++ libraries with Automake and Autoconf
These make understanding basic path of execution much easier and are an excellent pre-read before feeding your brain with official manuals.
Coming from Windows background I was a bit worried about the complexity of accessing Postgres databases from C++. I'm still having nightmares of early ODBC programming back in the 90ties. But as a mature developer I quickly overcame Microsoft's fixation on building the mother of all DBMS access technologies; that is - a common database mechanism to access various DBMSes.
Seriously, how many times in life have you ported a database from MS SQL Server to Oracle? There is a brilliang library for accessing Postgres (and only Postgres!) from C++ available. It is pqxx. It comes with a tutorial to help you getting started.
Here is Hello World of libpqxx. It doesn't get any simpler then that. Following code executes a query on a database.
- #include <pqxx/pqxx>
- using namespace pqxx;
- void execute_query() {
- connection cn("dbname=my_database");
- work w(cn, "mytransaction");
- w.exec("INSERT INTO city(city_name) VALUES ('Ljubljana');");
- w.commit();
- }
And now for something a bit more complex. Today we're going to discover the art of creating a stored procedure / function layer in Postgres database.
Let us first agree on terminology. In Postgres there is no difference between a stored procedure and a function. A procedure is merely a function returning void. Thus from now on we will only use term function.
Just in case you wonder - as a mature DBMS Postgres prepares (precompiles) all functions for optimal performance, exactly as its commercial competitors.In contemporary databases functions are commonly used to implement security layer. It is generally easier to give a user permission to execute a function that manipulates many database tables to complete a business operation then it is to assign him or her just the right permissions on all involved database tables for the same result.
Therefore modern designs introduce an additional layer of abstraction to access database tables. This layer is implemented via functions. In such scenario users can access database tables only through functions. They have no direct access to database tables.

To implement this design we need to know more about the Security of definer concept.
Security of definer
In Postgres a function can be defined to have “Security of definer” property set. You can set this propety in pgAdmin (see the screenshot bellow).

To set this property manually add SECURITY DEFINER to the end of function definition like this -
- CREATE FUNCTION insert_city(character varying)
- RETURNS void AS
- $BODY$
- BEGIN
- INSERT INTO city("name") VALUES($1);
- END
- $BODY$
- LANGUAGE 'plpgsql' VOLATILE SECURITY DEFINER;
Adding this to a function will make it run under the context of the owner of the function instead of context of the caller of the function. This allows a user to insert city into a table without having insert permission on it. As long as he has permission to execute this function and the owner of the function has permission to insert into city table. It is a way to implement chained security on Postgres.
Postgres functions that return datasets
Postgres functions that return data sets are poorly documented and their syntax might look a bit awkward to those of you used to SQL Server. When a function in Postgres returns multiple results it must be declared to return SETOF some type. Call syntax for such functions is a bit different then what you are used to. You call it using SELECT * FROM function() instead of usual SELECT function() call.
- SELECT function_returning_setof(); -- Wrong!
- SELECT * FROM function_returning_setop(); -- OK!
- SELECT function_returning_scalar(); -- OK
Let's imagine we have a table of all cities with two fields – city_id of type SERIAL, and name of type VARCHAR(80). Actually we're imagining this througout this article.
Here is a code fragment showing how to write a function returning all cities.
- CREATE FUNCTION list_all_cities()
- RETURNS SETOF city AS
- $$
- DECLARE
- rec record;
- BEGIN
- FOR rec IN (SELECT * FROM city) LOOP
- RETURN NEXT rec;
- END LOOP;
- END;
- $$ LANGUAGE plpgsql;
- -- Call the function.
- SELECT * FROM list_all_cities();
This code is using generic type called RECORD. Try experimenting with %ROWTYPE to obtain same results. Function above returns type SETOF city - each record in the set has the same structure as a record of city table. But what if you wanted to return another structure? One way is to create a type like this -
- CREATE TYPE list_all_city_names_result_type AS (city_name varchar(80));
- CREATE FUNCTION list_all_city_names()
- RETURNS SETOF list_all_city_names_result_type AS
- $$
- DECLARE
- rec record;
- BEGIN
- FOR rec IN (SELECT "name" FROM city) LOOP
- RETURN NEXT rec;
- END LOOP;
- END;
- $$ LANGUAGE plpgsql;
- SELECT * FROM list_all_city_names();
If this imposes too harsh limitations then you can also use the generic RECORD data type as return type and tell the procedure what to expect when calling it.
- CREATE FUNCTION list_all_city_names2()
- RETURNS SETOF RECORD AS
- $$
- DECLARE
- rec record;
- BEGIN
- FOR rec IN (SELECT "name" FROM city) LOOP
- RETURN NEXT rec;
- END LOOP;
- END;
- $$ LANGUAGE plpgsql;
- SELECT * FROM list_all_city_names2()
- AS ("city_name" varchar(80)); -- Expect varchar(80)
There's one more trick. I don't recommend it but I'm publishing it anyways. If you'd like to make things really simple for you then you could use another language instead of plpgsql. For example, using sql code you can write queries directly into your function like this -
- CREATE FUNCTION getallzipcodes()
- RETURNS SETOF zip AS
- $BODY$
- SELECT * FROM zip;
- $BODY$
- LANGUAGE 'sql';
Stored procedure layer and automatic code generation
When I create stored procedure layer I like to generate code for basic CRUD functions. I only write code for complex business functions by hand. Thus in my next article I am going to write code generator to do just that for Postgres/c++ pair.
But right now let's just explain some concepts. CRUD functions are - Create (new record from data), Read (given ID), Update (existing record given ID and new data) and Delete (given id) for single table. These functions are needed for every table. For example for table city you would have following functions:
- create_city(name),
- read_city(id),
- update_city(id,new_name),
- delete_city(id).
Two more types of functions are often needed. Get functions and list functions (sometimes called find functions). The difference between get and list function is that a get function always return single result. For example get_city_id_by_name(name) or get_user_by_phone(phone). Whereas list function returns all records that match the condition provided as parameters. For example - list_cities_starting_with(word) or list_persons_older_then(age) or list_all_countries().
Some people prefer list_ and other prefer find_ prefix for list functions. It is a matter of taste; as long as your programming stlye is consistent.
Table above shows functions that will be needed for almost any table and are therefore candidates for automatic code generation. We'll deal with code generation in one of our following articles.

If you would like to publish SQL or C++ code on your blog hosted by Blogger I recommend SyntaxHighlighter.
You can install the SyntaxHighlighter Blogger widget somewhere on your blog. I installed it at the bottom of this blog.
Use tag pre to publish your code. For example:
<pre name="code" class="SQL">
-- Sample
SELECT * FROM city;
</pre>
will produce this result
- -- Sample
- SELECT * FROM city;
Supported languages include c++, sql, c#, etc. All supported language tags can be found here.
When in Unix you should really do as Unixans do. They store application configuration to the /etc folder and user preferences to user's home folder using dot (.) for first name of file.
So if your application is called maestro then it should store its' configuration to /etc/maestro.conf (or /etc/maestro/config.xml or /etc/maestro/app.ini - it doesn't matter as long as it is in the /etc). And it should store its' user preferences to ~/.maestro file (or to ~/.maestro/.profile.txt - as long as it is in users' folder, starts with a dot and the filename hints about its origin).
Even Gnomes' GConf (you may run it from cmd line using gconf-editor) follows this convention by creating a ~/.gconf file in your home folder.

Your application should also be configurable via environment variables and command line parameters. But what if a collision of settings occur? Then you should use following priorities - low) read config file, mid) check the environment variables, high) check command line parameters.
Configuration source with highest priority should prevail. For example - if an option is defined in config file and is also passed as a command line parameter the one passed at the command line should be used.
Easiest way to implement all this is to try to read each settings from config file, then from environment vars and then from cmd line overwriting it each time a new value is available. This way the last read setting will prevail. There are multiple libraries available to assist you with reading config files and parsing command line parameters. Though options are many for C++ I recommend using Boost.Program_options. It will provide the user of your command line tool with experience he is familiar with including command line script files. I explained my preference for the Boost library here.
1. Casing conventions
These are compatible with pgAdmin generated code so I recommend you stick to them.
2. Identing rules
2.1. Set tab size to 8 (spaces).
2.2. Make it possible to comment out (using --) delimiters and operators (such as comma, AND, OR, JOIN, etc.) by putting them at the beginning of a row.
2.3. When dividing statements to multiple rows ident them to emphasize individual statements' hierarchy. 
2.4. Feel free to put entire SQL statement into single row if it will fit.
3. Academic sample from the internet
4. Real life sample (fragment!)